Burst User Guide
Burst is a compiler that translates from IL/.NET bytecode to highly optimized native code using LLVM. It is released as a Unity package and integrated into Unity using the Unity Package Manager.
Quick Start
Compile a Job with the Burst compiler
Burst is primarily designed to work efficiently with the Job system.
You can start using the Burst compiler in your code by simply decorating a Job struct with the attribute [BurstCompile]
using Unity.Burst;
using Unity.Collections;
using Unity.Jobs;
using UnityEngine;
public class MyBurst2Behavior : MonoBehaviour
{
void Start()
{
var input = new NativeArray<float>(10, Allocator.Persistent);
var output = new NativeArray<float>(1, Allocator.Persistent);
for (int i = 0; i < input.Length; i++)
input[i] = 1.0f * i;
var job = new MyJob
{
Input = input,
Output = output
};
job.Schedule().Complete();
Debug.Log("The result of the sum is: " + output[0]);
input.Dispose();
output.Dispose();
}
// Using BurstCompile to compile a Job with Burst
// Set CompileSynchronously to true to make sure that the method will not be compiled asynchronously
// but on the first schedule
[BurstCompile(CompileSynchronously = true)]
private struct MyJob : IJob
{
[ReadOnly]
public NativeArray<float> Input;
[WriteOnly]
public NativeArray<float> Output;
public void Execute()
{
float result = 0.0f;
for (int i = 0; i < Input.Length; i++)
{
result += Input[i];
}
Output[0] = result;
}
}
}
By default (only within the Editor - See AOT vs JIT), Burst JIT compiles jobs asynchronously, but the example above uses the option CompileSynchronously = true to make sure that the method is compiled on the first schedule. In general, you should use asynchronous compilation. See [BurstCompile] options
Jobs/Burst Menu
The Burst package adds a few menu entries to the Jobs menu for controlling Burst behavior:
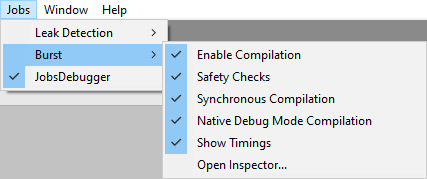
- Enable Compilation: When checked, Burst compiles Jobs and Burst custom delegates that are tagged with the attribute
[BurstCompile]. Default is checked. - Enable Safety Checks: When checked, Burst enables safety checks on code that uses collection containers (e.g
NativeArray<T>). Checks include job data dependency and container indexes out of bounds. Note that this option disables the noaliasing performance optimizations, by default. Default is checked. Safety checks are always restored toonwhen restarting the editor. - Synchronous Compilation: When checked, Burst will compile synchronously - See
[BurstCompile]options. Default is unchecked. - Native Debug Mode Compilation: When checked, Burst will disable optimizations on all code compiled, in order to make it easier to debug via a native debugger - See Native Debugging. Default is unchecked.
- Show Timings: When checked, Burst logs the time it takes to JIT compile a Job in the Editor. Default is unchecked.
- Open Inspector...: Opens the Burst Inspector Window.
Burst Inspector
The Burst Inspector window displays all the Jobs and other Burst compile targets in the project. Open the Inspector from the Jobs menu (Jobs > Burst Inspector).
The inspector allows you to view all the Jobs that can be compiled, you can also then check the generated intermediate and native assembly code.
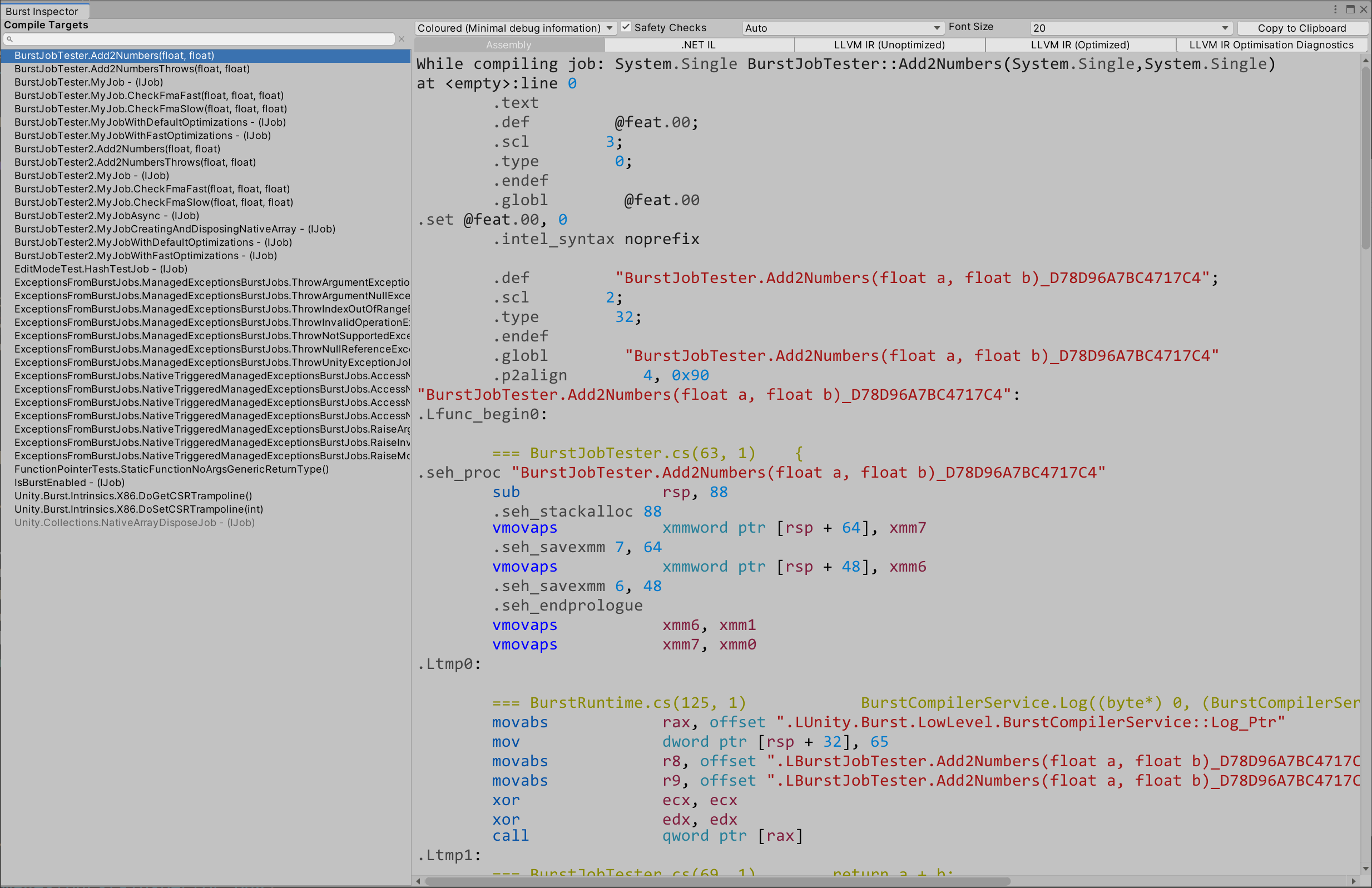
On the left pane of the window, Compile Targets provides an alphabetically sorted list of the Jobs in the project that Burst can compile. Note that the disabled Jobs in the list don't have the [BurstCompile] attribute.
On the right pane, the window displays options for viewing the assembly and intermediate code for the selected compile target.
To view the disassembly for a Job:
- Select an active compile target from the left pane.
- Switch between the different tabs to display the details:
- Assembly provides the final optimized native code generated by Burst
- .NET IL provides a view on the original .NET IL extracted from the Job method
- LLVM IR (Unoptimized) provides a view on the internal LLVM IR before optimizations.
- LLVM IR (Optimized) provides a view on the internal LLVM IR after optimizations.
- LLVM IR Optimization Diagnostics provides detailed LLVM diagnostics of the optimizations (i.e if they succeeded or failed).
- You can also turn on different options:
- There is a dropdown to specify what output to show. If you click the Copy to Clipboard button it'll copy the output that matches what you specify here (so if you have coloured output you'll get all the
<color=#444444>foo</color>tags). In general its best to view the coloured output in the inspector, but copy the plain output if you want to move it into an external tool. ** Plain (No debug information) - raw output. ** Plain (With debug information) - same as above but with debug information included too. ** Enhanced (Minimal debug information) - enhanced output has the line information interweaved with the assembly to guide you as to what line in your code matches what assembly output. ** Enhanced (Full debug information) - same as above but with debug information included too. ** Coloured (Minimal debug information) - same as the enhanced output but the assembly is colourised nicely to aid reading. ** Coloured (Full debug information) - same as above but with debug information included too. - The Safety Checks option generates code that includes container access safety checks (e.g check if a job is writing to a native container that is readonly).
- There is a dropdown to specify what output to show. If you click the Copy to Clipboard button it'll copy the output that matches what you specify here (so if you have coloured output you'll get all the
Command-line Options
You can pass the following options to the Unity Editor on the command line to control Burst:
-burst-disable-compilation— turns Burst off.-burst-force-sync-compilation— Burst always compiles synchronously. See[BurstCompile]options.
Just-In-Time (JIT) vs Ahead-Of-Time (AOT) Compilation
When working on your projects in the editor (play mode), burst works in a Just-In-Time (JIT) fashion. Burst will compile your code at the point that it is to be used. By default this is done asnychronously which means your code will be running under the default mono JIT until the compilation by burst has been completed.
You can control this behaviour via [BurstCompile] options.
However when you build your project into a Standalone Player, burst will instead compile all the supported code Ahead-Of-Time (AOT). AOT compilation at present, requires access to some linker tools for the respective platforms (similar to the requirements of IL2CPP). See Burst AOT Requirements.
See Standalone Player Support.
C#/.NET Language Support
Burst is working on a subset of .NET that doesn't allow the usage of any managed objects/reference types in your code (class in C#).
The following sections gives more details about the constructs actually supported by Burst.
Supported .NET types
Primitive types
Burst supports the following primitive types:
boolsbyte/byteshort/ushortint/uintlong/ulongfloatdouble
Burst does not support the following types:
char(this will be supported in a future release)stringas this is a managed typedecimal
Vector types
Burst is able to translate vector types from Unity.Mathematics to native SIMD vector types with first class support for optimizations:
bool2/bool3/bool4uint2/uint3/uint4int2/int3/int4float2/float3/float4
Note that for performance reasons, the 4 wide types (
float4,int4...) should be preferred
Enum types
Burst supports all enums including enums with a specific storage type (e.g public enum MyEnum : short)
Burst doesn't currently support
Enummethods (e.gEnum.HasFlag)
Struct types
Burst supports regular structs with any field with supported types.
Burst supports fixed array fields.
Regarding the layout, LayoutKind.Sequential and LayoutKind.Explicit are both supported
The
StructLayout.Packpacking size is not supported
The System.IntPtr and UIntPtr are supported natively as an intrinsic struct directly representing pointers.
Pointer types
Burst supports any pointer types to any Burst supported types
Generic types
Burst supports generic types used with structs. Specifically, it supports full instantiation of generic calls for generic types with interface constraints (e.g when a struct with a generic parameter requiring to implement an interface)
Note that there are restrictions when using Generic Jobs.
Array types
Managed arrays are not supported by Burst. You should use instead a native container, NativeArray<T> for instance.
Burst supports reading from readonly managed arrays loaded only from static readonly fields:
[BurstCompile]
public struct MyJob : IJob {
private static readonly int[] _preComputeTable = new int[] { 1, 2, 3, 4 };
public int Index { get; set; }
public void Execute()
{
int x = _preComputeTable[0];
int z = _preComputeTable[Index];
}
}
Accessing a static readonly managed array has with the following restrictions:
- You are not allowed to pass this static managed array around (e.g method argument), you have to use it directly.
- Elements of readonly static managed arrays should not be modified by a C# code external to jobs, as the Burst compiler makes a readonly copy of the data at compilation time.
- Array of structs are also supported on the condition that the struct constructor doesn't have any control flow (e.g
if/else) and/or does not throw an exception. - You cannot assign to static readonly array fields more than once in a static constructor.
- You cannot use explicitly laid out structs in static readonly array types.
Burst will produce the error BC1361 for any of these static constructors that we cannot support.
Language Support
Burst supports most of the expressions and statements:
- Regular C# control flows:
if/else/switch/case/for/while/break/continue.
- Extension methods.
- Unsafe code, pointers manipulation...etc.
- Instance methods of structs.
- By ref/out parameters.
DllImportand internal calls.- Limited support for
throwexpressions, assuming simple throw patterns (e.gthrow new ArgumentException("Invalid argument")). In that case, we will try to extract the static string exception message to include it in the generated code. - Some special IL opcodes like
cpblk,initblk,sizeof. - Loading from static readonly fields.
- Support for
fixedstatements. - Partial support for strings and
Debug.Log.
Burst provides also alternatives for some C# constructions not directly accessible to HPC#:
- Function pointers as an alternative to using delegates within HPC#
- Shared Static to access static mutable data from both C# and HPC#
Burst does not support:
catchtry/finally(which will come at some point)foreachas it is requiringtry/finally(This should be supported in a future version)- Storing to static fields except via Shared Static
- Any methods related to managed objects (e.g string methods...etc.)
Partial support for strings and Debug.Log
Burst provides partial support for using strings in the following two main scenarios:
Debug.Log(see below)- Assignment of a string to various FixedString structs provided by
Unity.Collections(e.gFixedString128)
A string can be either:
- A string literal (e.g
"This is a string literal"). - An interpolated string (using
$"This is an integer {value}or usingstring.Format) where the string to format is also a string literal
For example, the following constructions are supported:
- Logging with a string literal:
Debug.Log("This a string literal");
- Logging using string interpolation:
int value = 256;
Debug.Log($"This is an integer value {value}");
Which is equivalent to using string.Format directly:
int value = 256;
Debug.Log(string.Format("This is an integer value {0}", value));
While it is possible to pass a managed string literal or an interpolated string directly to Debug.Log, it is not possible to pass a string to a user method or to use them as fields in a struct. In order to pass or store strings around, you need to use one of the FixedString structs provided by the Unity.Collections package:
int value = 256;
FixedString128 text = $"This is an integer value {value} used with FixedString128";
MyCustomLog(text);
// ...
// String can be passed as an argument to a method using a FixedString,
// but not using directly a managed `string`:
public static void MyCustomLog(in FixedString128 log)
{
Debug.Log(text);
}
Burst has limited support for string format arguments and specifiers:
int value = 256;
// Padding left: "This value ` 256`
Debug.Log($"This value `{value,5}`");
// Padding right: "This value `256 `
Debug.Log($"This value `{value,-5}`");
// Hexadecimal uppercase: "This value `00FF`
Debug.Log($"This value `{value:X4}`");
// Hexadecimal lowercase: "This value `00ff`
Debug.Log($"This value `{value:x4}`");
// Decimal with leading-zero: "This value `0256`
Debug.Log($"This value `{value:D4}`");
What is supported currently:
- The following
Debug.Logmethods:Debug.Log(object)Debug.LogWarning(object)Debug.LogError(object)
- String interpolation is working with the following caveats:
- The string to format must be a literal.
- Only the following
string.Formatmethods are supported:string.Format(string, object),string.Format(string, object, object),string.Format(string, object, object, object)and more if the .NET API provides specializations with object arguments.string.Format(string, object[]): which can happen for a string interpolation that would contain more than 3 arguments (e.g$"{arg1} {arg2} {arg3} {arg4} {arg5}..."). In that case, we expect the object[] array to be of a constant size and no arguments should involve control flows (e.g$"This is a {(cond ? arg1 : arg2)}")
- Only value types.
- Primitive types only arguments:
char,boolean,byte,sbyte,ushort,short,uint,int,ulong,long,float,double. - All vector types e.g
int2,float3are supported, excepthalfvector types.c# var value = new float3(1.0f, 2.0f, 3.0f); // Logs "This value float3(1f, 2f, 3f)" Debug.Log($"This value `{value}`"); - Does not support
ToString()of structs. It will display the full name of the struct instead.
- The supported string format specifiers are only
G,g,D,dandX,x, with padding and specifier. For more details:
Intrinsics
System.Math
Burst provides an intrinsic for all methods declared by System.Math except for the following methods that are not supported:
double IEEERemainder(double x, double y)Round(double value, int digits)
System.IntPtr
Burst supports all methods of System.IntPtr/System.UIntPtr, including the static fields IntPtr.Zero and IntPtr.Size
System.Threading.Interlocked
Burst supports atomic memory intrinsics for all methods provided by System.Threading.Interlocked (e.g Interlocked.Increment...etc.)
Care must be taken when using the interlocked methods that the source location being atomically accessed is naturally aligned - EG. the alignment of the pointer is a multiple of the pointed-to-type.
For example:
[StructLayout(LayoutKind.Explicit)]
struct Foo
{
[FieldOffset(0)] public long a;
[FieldOffset(5)] public long b;
public long AtomicReadAndAdd()
{
return Interlocked.Read(ref a) + Interlocked.Read(ref b);
}
}
And lets assume that the pointer to the struct Foo has an alignment of 8 - the natural alignment of a long value. The Interlocked.Read of a would be successful because it lies on a naturally aligned address, but b would not. Undefined behaviour will occur at the load of b as a result.
System.Threading.Thread
Burst supports the MemoryBarrier method of System.Threading.Thread.
System.Threading.Volatile
Burst supports the non-generic variants of Read and Write provided by System.Threading.Volatile.
Unity.Burst.Intrinsics
Burst provides low level close-to-the-metal intrinsics via the Unity.Burst.Intrinsics namespace.
Common
The Unity.Burst.Intrinsics.Common intrinsics are for functionality that is shared across the hardware targets that Burst supports.
Pause
The Unity.Burst.Intrinsics.Common.Pause is an experimental intrinsic that provides a hint that the current thread should pause. It maps to pause on x86, and yield on ARM.
It is used primarily to stop spin locks over contending on an atomic access, to reduce contention and power on that section of code.
The intrinsic is experimental and so guarded by the UNITY_BURST_EXPERIMENTAL_PAUSE_INTRINSIC preprocessor define.
Prefetch
The Unity.Burst.Intrinsics.Common.Prefetch is an experimental intrinsic that provides a hint that the a memory location should be prefetched into the cache.
The intrinsic is experimental and so guarded by the UNITY_BURST_EXPERIMENTAL_PREFETCH_INTRINSIC preprocessor define.
umul128
The Unity.Burst.Intrinsics.Common.umul128 is an intrinsic that enables users to access 128-bit unsigned multiplication. These multiplies have become increasingly prevalent in hashing functions. It maps 1:1 with hardware instructions on x86 and ARM targets.
Processor specific SIMD extensions
Burst exposes all Intel SIMD intrinsics from SSE and up to and including AVX2,
by means of the Unity.Burst.Intrinsics.X86 family of nested classes. These
are intended to be statically imported as they are plain functions:
using static Unity.Burst.Intrinsics.X86;
using static Unity.Burst.Intrinsics.X86.Sse;
using static Unity.Burst.Intrinsics.X86.Sse2;
using static Unity.Burst.Intrinsics.X86.Sse3;
using static Unity.Burst.Intrinsics.X86.Ssse3;
using static Unity.Burst.Intrinsics.X86.Sse4_1;
using static Unity.Burst.Intrinsics.X86.Sse4_2;
using static Unity.Burst.Intrinsics.X86.Popcnt;
using static Unity.Burst.Intrinsics.X86.Avx;
using static Unity.Burst.Intrinsics.X86.Avx2;
using static Unity.Burst.Intrinsics.X86.Fma;
using static Unity.Burst.Intrinsics.X86.F16C;
Each feature level above provides a compile-time check to test if the feature level is present at compile-time:
if (IsAvx2Supported)
{
// Code path for AVX2 instructions
}
else if (IsSse42Supported)
{
// Code path for SSE4.2 instructions
}
else
{
// Fallback path for everything else
}
Later feature levels implicitly include the previous ones, so tests must be organized from most recent to least recent. Burst will emit compile-time errors if there are uses of intrinsics that are not part of the current compilation target which are also not bracketed with a feature level test, helping you to narrow in on what needs to be put inside a feature test.
Note that when running in .NET, Mono or IL2CPP without Burst enabled, all the IsXXXSupported properties will return false.
However, if you skip the test you can still run a reference version of most
intrinsics in Mono (exceptions listed below), which can be helpful if you need to use the managed
debugger. Please note however that the reference implementations are very slow
and only intended for managed debugging.
Note that the FMA intrinsics that operate on doubles do not have a software fallback because of the inherit complexity in emulating fused 64-bit floating point math.
Intrinsic usage is relatively straightforward and is based on the types v128
and v256, which represent a 128-bit or 256-bit vector respectively. For example,
given a NativeArray<float> and a Lut lookup table of v128 shuffle masks,
a code fragment like this performs lane left packing, demonstrating the use
of vector load/store reinterpretation and direct intrinsic calls:
v128 a = Input.ReinterpretLoad<v128>(i);
v128 mask = cmplt_ps(a, Limit);
int m = movemask_ps(a);
v128 packed = shuffle_epi8(a, Lut[m]);
Output.ReinterpretStore(outputIndex, packed);
outputIndex += popcnt_u32((uint)m);
In general the API mirrors the C/C++ Intel instrinsics API, with a few mostly mechanical differences:
- All 128-bit vector types (
__m128,__m128iand__m128d) have been collapsed intov128 - All 256-bit vector types (
__m256,__m256iand__m256d) have been collapsed intov256 - All
_mmprefixes on instructions and macros have been dropped, as C# has namespaces - All bitfield constants (for e.g. rounding mode selection) have been replaced with C# bitflag enum values
DllImport and internal calls
Burst supports calling native functions via [DllImport]:
[DllImport("MyNativeLibrary")]
public static extern int Foo(int arg);
as well as "internal" calls implemented inside Unity:
// In UnityEngine.Mathf
[MethodImpl(MethodImplOptions.InternalCall)]
public static extern int ClosestPowerOfTwo(int value);
For all DllImport and internal calls, only types in the following list can be used as
parameter or return types:
- Primitive and intrinsic types
byteushortuintulongsbyteshortintlongfloatdoubleSystem.IntPtrSystem.UIntPtrUnity.Burst.Intrinsics.v64Unity.Burst.Intrinsics.v128Unity.Burst.Intrinsics.v256
- Pointers and references
sometype*- Pointer to any of the other types in this listref sometype- Reference to any of the other types in this list
- "Handle" structs
unsafe struct MyStruct { void* Ptr; }- Struct containing a single pointer fieldunsafe struct MyStruct { int Value; }- Struct containing a single integer field
Note that passing structs by value is not supported; you need to pass them through a pointer or reference. The only exception is that "handle" structs are supported - these are structs that contain a single field, of pointer or integer type.
Known issues with DllImport
DllImportis not available on 32-bit or Arm platforms, with the exception thatDllImport("__Internal")is supported on statically linked platforms (iOS).DllImportis only supported for native plugins, not platform-dependent libraries likekernel32.dll.
Debugging
Burst now provides support for debugging using a native debugger (for instance Visual Studio Community). Managed debugging is currently not supported.
Managed debugging
NOTE: Burst does not provide currently a dedicated debugger for Burst compiled Jobs.
If you need to debug a job, you will need to disable the Burst compiler or comment the
[BurstCompile]attribute from your job and attach a regular .NET managed debugger
Native debugging
Burst compiled code can be debugged using a native debugger, by simply attaching the native debugger to the Unity process. However due to the optimisations employed by Burst, you will generally find it easier to debug by ensuring your code is compiled with Native debuggers in mind.
You can do this either via the Jobs menu Jobs Menu which will compile the code with native debugging enabled globally (this disables optimizations, so will impact performance of Burst code).
Alternatively, you can use the Debug=true option in the [BurstCompile] attribute for your job e.g.
[BurstCompile(Debug=true)]
public struct MyJob : IJob
{
// ...
}
Which will then only affect optimizations (and debuggability) on that job. Note standalone player builds will currently also pick up the Debug flag, so standalone builds can be debugged this way too.
Burst also supports code-based breakpoints via the System.Diagnostics.Debugger.Break() which will generate a debug trap into the code. Note that if you do this you should ensure you have a debugger attached to intercept the break. At present the breakpoints will trigger whether a debugger is attached or not.
Burst adds information to track local variables, function parameters and breakpoints. If your debugger supports conditional breakpoints, these are preferable to inserting breakpoints in code, since they will only fire when a debugger is attached.
Known issues with debugging
- Lambda captures on
Entity.ForEach()are not discovered for debugging data, so you won't be able to inspect variables originating from these. - Structs that utilize
LayoutKind=Explicit, and have overlapping fields, are represented by a struct that will hide one of the overlaps. In the future they will be represented as a union of structs, to allow inspection of fields that overlap. - Function parameters are currently readonly from a debugging point of view. They are recorded to a stack argument during the prologue. Changing their value in the debugger may not have an affect.
Advanced usages
BurstDiscard attribute
When running some code in the full C# (not inside a Burst compiled code), you may want to use some managed objects but you would like to not compile these portion of code when compiling within Burst.
To mitigate this, you can use the [BurstDiscard] attribute on a method:
[BurstCompile]
public struct MyJob : IJob
{
public void Execute()
{
// Only executed when running from a full .NET runtime
// this method call will be discard when compiling this job with
// [BurstCompile] attribute
MethodToDiscard();
}
[BurstDiscard]
private static void MethodToDiscard(int arg)
{
Debug.Log($"This is a test: {arg}");
}
}
A method with
[BurstDiscard]cannot have a return value or anref/outparameter
Synchronous Compilation
By default, the Burst compiler in the editor will compile the jobs asynchronously.
You can change this behavior by setting CompileSynchronously = true for the [BurstCompile] attribute:
[BurstCompile(CompileSynchronously = true)]
public struct MyJob : IJob
{
// ...
}
When running a Burst job in the editor, the first attempt to call the job will cause the asynchronous compilation of the Burst job to be kicked off in the background, while running the managed C# job in the mean time. This minimizes any frame hitching and keeps the experience for you and your users responsive.
When CompileSynchronously = true is set, no asynchronous compilation can occur. Burst is focused on providing highly performance oriented code-generation and as a result will take a little longer than a traditional JIT to compile. Crucially this pause for compilation will affect the current running frame, meaning that hitches can occur and it could provide an unresponsive experience for users. In general the only legitimate uses of CompileSynchronously = true are:
- If you have a long running job that will only run once, the performance of the compiled code could out-weigh the cost of doing the compilation.
- If you are profiling a Burst job and thus want to be certain that the code that is being tested is from the Burst compiler. In this scenario you should perform a warmup to throw away any timing measurements from the first call to the job as that would include the compilation cost and skew the result.
- If you suspect that there are some crucial differences between managed and Burst compiled code. This is really only as a debugging aid, as the Burst compiler strives to match any and all behaviour that managed code could produce.
Function Pointers
It is often required to work with dynamic functions that can process data based on other data states. In that case, a user would expect to use C# delegates but in Burst, because these delegates are managed objects, we need to provide a HPC# compatible alternative. In that case you can use FunctionPointer<T>.
First you need identify the static functions that will be compiled with Burst:
- add a
[BurstCompile]attribute to these functions - add a
[BurstCompile]attribute to the containing type. This attribute is only here to help the Burst compiler to look for static methods with[BurstCompile]attribute - create the "interface" of these functions by declaring a delegate
- add a
[MonoPInvokeCallbackAttribute]attribute to the functions, as it is required to work properly with IL2CPP:
// Instruct Burst to look for static methods with [BurstCompile] attribute
[BurstCompile]
class EnclosingType {
[BurstCompile]
[MonoPInvokeCallback(typeof(Process2FloatsDelegate))]
public static float MultiplyFloat(float a, float b) => a * b;
[BurstCompile]
[MonoPInvokeCallback(typeof(Process2FloatsDelegate))]
public static float AddFloat(float a, float b) => a + b;
// A common interface for both MultiplyFloat and AddFloat methods
public delegate float Process2FloatsDelegate(float a, float b);
}
Then you need to compile these function pointers from regular C# code:
// Contains a compiled version of MultiplyFloat with burst
FunctionPointer<Process2FloatsDelegate> mulFunctionPointer = BurstCompiler.CompileFunctionPointer<Process2FloatsDelegate>(MultiplyFloat);
// Contains a compiled version of AddFloat with burst
FunctionPointer<Process2FloatsDelegate> addFunctionPointer = BurstCompiler.CompileFunctionPointer<Process2FloatsDelegate>(AddFloat);
Lastly, you can use these function pointers directly from a Job by passing them to the Job struct directly:
// Invoke the function pointers from HPC# jobs
var resultMul = mulFunctionPointer.Invoke(1.0f, 2.0f);
var resultAdd = addFunctionPointer.Invoke(1.0f, 2.0f);
Note that you can also use these function pointers from regular C# as well, but it is highly recommended (for performance reasons) to cache the FunctionPointer<T>.Invoke property (which is the delegate instance) to a static field.
private readonly static Process2FloatsDelegate mulFunctionPointerInvoke = BurstCompiler.CompileFunctionPointer<Process2FloatsDelegate>(MultiplyFloat).Invoke;
// Invoke the delegate from C#
var resultMul = mulFunctionPointerInvoke(1.0f, 2.0f);
A few important additional notes:
- Function pointers are compiled asynchronously by default as for jobs. You can still force a synchronous compilation of function pointers by specifying this via the
[BurstCompile(SynchronousCompilation = true)].- Function pointers have limited support for exceptions. As is the case for jobs, exceptions only work in the editor (
2019.3+only) and they will result in a crash if they are used within a standalone player. It is recommended not to rely on any logic related to exception handling when working with function pointers.- Using Burst-compiled function pointers from C# could be slower than their pure C# version counterparts if the function is too small compared to the cost of P/Invoke interop.
- A function pointer compiled with Burst cannot be called directly from another function pointer. This limitation will be lifted in a future release. You can workaround this limitation by creating a wrapper function with the
[BurstCompile]attribute and to use the shared function from there.- Function pointers don't support generic delegates.
- Argument and return types are subject to the same restrictions as described for
DllImportand internal calls.
Performance Considerations
If you are ever considering using Burst's function pointers, you should always first consider whether a job would better. Jobs are the most optimal way to run code produced by the Burst compiler for a few reasons:
- The superior aliasing calculations that Burst can provide with a job because of the rules imposed by the job safety system allow for much more optimizations by default.
- You cannot pass most of the
[NativeContainer]structs likeNativeArraydirectly to function pointers, only via Job structs. The native container structs contain managed objects for safety checks that the Burst compiler can work around when compiling jobs, but not for function pointers. - Function pointers hamper the compiler's ability to optimize across functions.
Let's look at an example of how not to use function pointers in Burst:
[BurstCompile]
public class MyFunctionPointers
{
public unsafe delegate void MyFunctionPointerDelegate(float* input, float* output);
[BurstCompile]
public static unsafe void MyFunctionPointer(float* input, float* output)
{
*output = math.sqrt(*input);
}
}
[BurstCompile]
struct MyJob : IJobParallelFor
{
public FunctionPointer<MyFunctionPointers.MyFunctionPointerDelegate> FunctionPointer;
[ReadOnly] public NativeArray<float> Input;
[WriteOnly] public NativeArray<float> Output;
public unsafe void Execute(int index)
{
var inputPtr = (float*)Input.GetUnsafeReadOnlyPtr();
var outputPtr = (float*)Output.GetUnsafePtr();
FunctionPointer.Invoke(inputPtr + index, outputPtr + index);
}
}
In this example we've got a function pointer that is computing math.sqrt from an input pointer, and storing it to an output pointer. The MyJob job is then feeding this function pointer sourced from two NativeArrays. There are a few major performance problems with this example:
- The function pointer is being fed a single scalar element, thus the compiler cannot vectorize. This means you are losing 4-8x performance straight away from a lack of vectorization.
- The
MyJobknows that theInputandOutputnative arrays cannot alias, but this information is not communicated to the function pointer. - There is a non-zero cost to constantly branching to a function pointer somewhere else in memory. Modern processors do a decent job at eliding this cost, but it is still non-zero.
If you feel like you must use function pointers, then you should always process batches of data in the function pointer. Let's modify the example above to do just that:
[BurstCompile]
public class MyFunctionPointers
{
public unsafe delegate void MyFunctionPointerDelegate(int count, float* input, float* output);
[BurstCompile]
public static unsafe void MyFunctionPointer(int count, float* input, float* output)
{
for (int i = 0; i < count; i++)
{
output[i] = math.sqrt(input[i]);
}
}
}
[BurstCompile]
struct MyJob : IJobParallelForBatch
{
public FunctionPointer<MyFunctionPointers.MyFunctionPointerDelegate> FunctionPointer;
[ReadOnly] public NativeArray<float> Input;
[WriteOnly] public NativeArray<float> Output;
public unsafe void Execute(int index, int count)
{
var inputPtr = (float*)Input.GetUnsafeReadOnlyPtr() + index;
var outputPtr = (float*)Output.GetUnsafePtr() + index;
FunctionPointer.Invoke(count, inputPtr, outputPtr);
}
}
In our modified MyFunctionPointer you can see that it takes a count of elements to process, and loops over the input and output pointers to do many calculations. The MyJob becomes an IJobParallelForBatch, and the count is passed directly into the function pointer. This is better for performance:
- You now get vectorization in the
MyFunctionPointercall. - Because you are processing
countitems per function pointer, any cost of calling the function pointer is reduced bycounttimes (EG. if you run a batch of 128, the function pointer cost is 1/128th perindexof what it was previously). - Doing the batching above realized a 1.53x performance gain over not batching, so it's a big win.
The best thing you can do though is just to use a job - this gives the compiler the most visibility over what you want it to do, and the most opportunities to optimize:
[BurstCompile]
struct MyJob : IJobParallelFor
{
[ReadOnly] public NativeArray<float> Input;
[WriteOnly] public NativeArray<float> Output;
public unsafe void Execute(int index)
{
Output[i] = math.sqrt(Input[i]);
}
}
The above will run 1.26x faster than the batched function pointer example, and 1.93x faster than the non-batched function pointer examples above. The compiler has perfect aliasing knowledge and can make the broadest modifications to the above. Note: this code is also significantly simpler than either of the function pointer cases, and shows that often the simplest solution provides the performance-by-default that Burst so strives for.
Shared Static
Burst has basic support for accessing static readonly data, but if you want to share static mutable data between C# and HPC#, you need to use the SharedStatic<T> struct.
Let's take the example of accessing an int static field that could be changed by both C# and HPC#:
public abstract class MutableStaticTest
{
public static readonly SharedStatic<int> IntField = SharedStatic<int>.GetOrCreate<MutableStaticTest, IntFieldKey>();
// Define a Key type to identify IntField
private class IntFieldKey {}
}
that can then be accessed from C# and HPC#:
// Write to a shared static
MutableStaticTest.IntField.Data = 5;
// Read from a shared static
var value = 1 + MutableStaticTest.IntField.Data;
A few important additional notes:
- The type of the data is defined by the
TinSharedStatic<T>.- In order to identify a static field, you need to provide a context for it: the common way to solve this is to create a key for both the containing type (e.g
MutableStaticTestin our example above) and to identify the field (e.gIntFieldKeyclass in our example) and by passing these classes as generic arguments ofSharedStatic<int>.GetOrCreate<MutableStaticTest, IntFieldKey>().- It is recommended to always initialize the shared static field in C# from a static constructor before accessing it from HPC#. Not initializing the data before accessing it can lead to an undefined initialization state.
Dynamic dispatch based on runtime CPU features
For all x86/x64 CPU desktop platforms, Burst will dispatch jobs to different version compiled by taking into account CPU features available at runtime.
Currently for for x86 and x64 CPU, Burst is supporting at runtime only SSE2 and SSE4 instruction sets.
For example, with dynamic CPU dispatch, if your CPU is supports SSE3 and below, Burst will select SSE2 automatically.
See the table in the section Burst AOT Requirements for more details about the supported CPU architectures.
Optimization Guidelines
Memory Aliasing and noalias
Memory aliasing is an important concept that can lead to significant optimizations for a compiler that is aware about how data is being used by the code.
The problem
Let's take a simple example of a job copying data from an input array to an output array:
[BurstCompile]
private struct CopyJob : IJob
{
[ReadOnly]
public NativeArray<float> Input;
[WriteOnly]
public NativeArray<float> Output;
public void Execute()
{
for (int i = 0; i < Input.Length; i++)
{
Output[i] = Input[i];
}
}
}
No memory aliasing:
If the two arrays Input and Output are not slightly overlapping, meaning that their respective memory location are not aliasing, we will get the following result after running this job on a sample input/output:
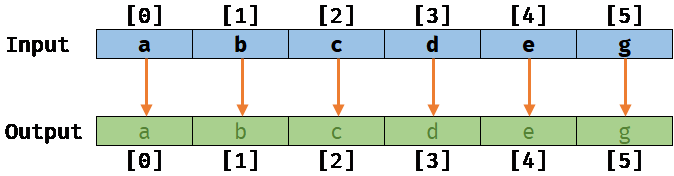
No memory aliasing with the auto-vectorizer:
Now, if the compiler is noalias aware, it will be able to optimize the previous scalar loop (working at a scalar level) by what is called vectorizing: The compiler will rewrite the loop on your behalf to process elements by a small batch (working at a vector level, 4 by 4 elements for example) like this:
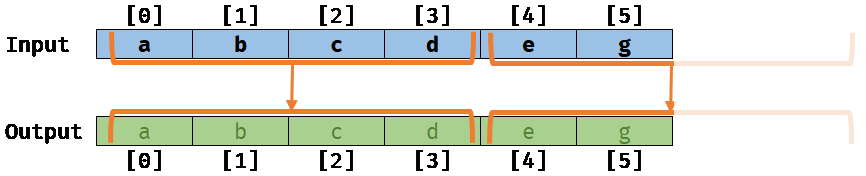
Memory aliasing:
Next, if for some reasons (that is not directly easy to introduce with the JobSystem today), the Output array is actually overlapping the Input array by one element off (e.g Output[0] points actually to Input[1]) meaning that memory are aliasing, we will get the following result when running the CopyJob (assuming that the auto-vectorizer is not running):
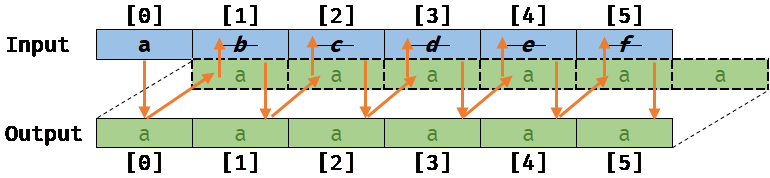
Memory aliasing with invalid vectorized code:
Worse, if the compiler was not aware of this memory aliasing, it would still try to auto-vectorize the loop, and we would get the following result, which is different from the previous scalar version:
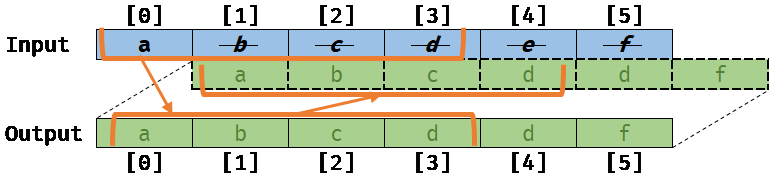
The result of this code would be invalid and could lead to very serious bugs if they are not identified by the compiler.
Example of Generated Code
Let's take the example of the x64 assembly targeted at AVX2 for the loop in the CopyJob above:
.LBB0_4:
vmovups ymm0, ymmword ptr [rcx - 96]
vmovups ymm1, ymmword ptr [rcx - 64]
vmovups ymm2, ymmword ptr [rcx - 32]
vmovups ymm3, ymmword ptr [rcx]
vmovups ymmword ptr [rdx - 96], ymm0
vmovups ymmword ptr [rdx - 64], ymm1
vmovups ymmword ptr [rdx - 32], ymm2
vmovups ymmword ptr [rdx], ymm3
sub rdx, -128
sub rcx, -128
add rsi, -32
jne .LBB0_4
test r10d, r10d
je .LBB0_8
As can be seen, the instruction vmovups is moving 8 floats here, so a single auto-vectorized loop is now moving 4 x 8 = 32 floats copied per loop iteration instead of just one!
If we compile the same loop but artificially disable Burst's knowledge of aliasing, we get the following code:
.LBB0_2:
mov r8, qword ptr [rcx]
mov rdx, qword ptr [rcx + 16]
cdqe
mov edx, dword ptr [rdx + 4*rax]
mov dword ptr [r8 + 4*rax], edx
inc eax
cmp eax, dword ptr [rcx + 8]
jl .LBB0_2
Which is entirely scalar, and will run roughly 32 times slower than the highly optimized vectorized variant that our alias analysis can produce.
Burst and the JobSystem
Unity's job-system infrastructure imposes certain rules on what can alias within a job struct:
- Structs attributed with
[NativeContainer], for exampleNativeArrayandNativeSlice, that are members of a job struct do not alias. - But job struct members with the
[NativeDisableContainerSafetyRestriction]attribute, these can alias with other members (because you as the user have explicitly opted in to this aliasing). - Pointers to structs attributed with
[NativeContainer]cannot appear within other structs attributed with[NativeContainer]. For example you cannot have aNativeArray<NativeSlice<T>>. This kind of spaghetti code is awful for optimizing compilers to understand.
Let us now look at an example job:
[BurstCompile]
private struct MyJob : IJob
{
public NativeArray<float> a;
public NativeArray<float> b;
public NativeSlice<int> c;
[NativeDisableContainerSafetyRestriction]
public NativeArray<byte> d;
public void Execute() { ... }
}
In the above example:
a,b, andcdo not alias with each other.- But
dcan alias witha,b, orc.
Those of you used to C/C++'s Type Based Alias Analysis (TBAA) might think 'But d has a different type from a, b, or c, so it should not alias!' - pointers in C# do not have any assumption that pointing to a different type results in no aliasing though. So d must be assumed to alias with a, b, or c.
The NoAlias Attribute
Burst has a [NoAlias] attribute that can be used to give the compiler additional information on the aliasing of pointers and structs. There are four uses of this attribute:
- On a function parameter it signifies that the parameter does not alias with any other parameter to the function.
- On a struct field it signifies that the field does not alias with any other field of the struct.
- On a struct itself it signifies that the address of the struct cannot appear within the struct itself.
- On a function return value it signifies that the returned pointer does not alias with any other pointer returned from the same function.
These attributes do not need to be used when dealing with [NativeContainer] attributed structs, or with fields in job structs - the Burst compiler is smart enough to infer the no-alias information about these without manual intervention from you, our users. This leads onto a general rule of thumb - the use of the [NoAlias] attribute is generally not required for user code, and we advise against its use. The attribute is exposed primarily for those constructing complex data structures where the aliasing cannot be inferred by the compiler. Any use of [NoAlias] on a pointer that could alias with another could result in undefined behaviour and hard to track down bugs.
NoAlias Function Parameter
Lets take a look at the following classic aliasing example:
int Foo(ref int a, ref int b)
{
b = 13;
a = 42;
return b;
}
For this the compiler produces the following assembly:
mov dword ptr [rdx], 13
mov dword ptr [rcx], 42
mov eax, dword ptr [rdx]
ret
As can be seen it:
- Stores 13 into
b. - Stores 42 into
a. - Reloads the value from
bto return it.
It has to reload b because the compiler does not know whether a and b are backed by the same memory or not.
Let's now add a [NoAlias] attribute and see what we get:
int Foo([NoAlias] ref int a, ref int b)
{
b = 13;
a = 42;
return b;
}
Which turns into:
mov dword ptr [rdx], 13
mov dword ptr [rcx], 42
mov eax, 13
ret
Notice that the load from b has been replaced with moving the constant 13 into the return register.
NoAlias Struct Field
Let's take the same example from above but apply it to a struct instead:
struct Bar
{
public NativeArray<int> a;
public NativeArray<float> b;
}
int Foo(ref Bar bar)
{
bar.b[0] = 42.0f;
bar.a[0] = 13;
return (int)bar.b[0];
}
The above produces the following assembly:
mov rax, qword ptr [rcx + 16]
mov dword ptr [rax], 1109917696
mov rcx, qword ptr [rcx]
mov dword ptr [rcx], 13
cvttss2si eax, dword ptr [rax]
ret
As can be seen it:
- Loads the address of the data in
bintorax. - Stores 42 into it (1109917696 is 0x42280000 which is 42.0f).
- Loads the address of the data in
aintorcx. - Stores 13 into it.
- Reloads the data in
band converts it to an integer for returning.
Let's assume that you as the user know that the two NativeArray's are not backed by the same memory, you could:
struct Bar
{
[NoAlias]
public NativeArray<int> a;
[NoAlias]
public NativeArray<float> b;
}
int Foo(ref Bar bar)
{
bar.b[0] = 42.0f;
bar.a[0] = 13;
return (int)bar.b[0];
}
By attributing both a and b with [NoAlias] we have told the compiler that they definitely do not alias with each other within the struct, which produces the following assembly:
mov rax, qword ptr [rcx + 16]
mov dword ptr [rax], 1109917696
mov rax, qword ptr [rcx]
mov dword ptr [rax], 13
mov eax, 42
ret
Notice that the compiler can now just return the integer constant 42!
NoAlias Struct
Nearly all structs you will create as a user will be able to have the assumption that the pointer to the struct does not appear within the struct itself. Let's take a look at a classic example where this is not true:
unsafe struct CircularList
{
public CircularList* next;
public CircularList()
{
// The 'empty' list just points to itself.
next = this;
}
}
Lists are one of the few structures where it is normal to have the pointer to the struct accessible from somewhere within the struct itself.
Now onto a more concrete example of where [NoAlias] on a struct can help:
unsafe struct Bar
{
public int i;
public void* p;
}
float Foo(ref Bar bar)
{
*(int*)bar.p = 42;
return ((float*)bar.p)[bar.i];
}
Which produces the following assembly:
mov rax, qword ptr [rcx + 8]
mov dword ptr [rax], 42
mov rax, qword ptr [rcx + 8]
mov ecx, dword ptr [rcx]
movss xmm0, dword ptr [rax + 4*rcx]
ret
As can be seen it:
- Loads
pintorax. - Stores 42 into
p. - Loads
pintoraxagain. - Loads
iintoecx. - Returns the index into
pbyi.
Notice that it loaded p twice - why? The reason is that the compiler does not know whether p points to the address of the struct bar itself - so once it has stored 42 into p, it has to reload the address of p from bar, just incase. A wasted load!
Lets add [NoAlias] now:
[NoAlias]
unsafe struct Bar
{
public int i;
public void* p;
}
float Foo(ref Bar bar)
{
*(int*)bar.p = 42;
return ((float*)bar.p)[bar.i];
}
Which produces the following assembly:
mov rax, qword ptr [rcx + 8]
mov dword ptr [rax], 42
mov ecx, dword ptr [rcx]
movss xmm0, dword ptr [rax + 4*rcx]
ret
Notice that it only loaded the address of p once, because we've told the compiler that p cannot be the pointer to bar!
NoAlias Function Return
Some functions can only return a unique pointer. For instance, malloc will only ever give you a unique pointer. For these cases [return:NoAlias] can provide the compiler with some useful information.
Lets take an example using a bump allocator backed with a stack allocation:
// Only ever returns a unique address into the stackalloc'ed memory.
// We've made this no-inline as the compiler will always try and inline
// small functions like these, which would defeat the purpose of this
// example!
[MethodImpl(MethodImplOptions.NoInlining)]
unsafe int* BumpAlloc(int* alloca)
{
int location = alloca[0]++;
return alloca + location;
}
unsafe int Func()
{
int* alloca = stackalloc int[128];
// Store our size at the start of the alloca.
alloca[0] = 1;
int* ptr1 = BumpAlloc(alloca);
int* ptr2 = BumpAlloc(alloca);
*ptr1 = 42;
*ptr2 = 13;
return *ptr1;
}
Which produces the following assembly:
push rsi
push rdi
push rbx
sub rsp, 544
lea rcx, [rsp + 36]
movabs rax, offset memset
mov r8d, 508
xor edx, edx
call rax
mov dword ptr [rsp + 32], 1
movabs rbx, offset "BumpAlloc(int* alloca)"
lea rsi, [rsp + 32]
mov rcx, rsi
call rbx
mov rdi, rax
mov rcx, rsi
call rbx
mov dword ptr [rdi], 42
mov dword ptr [rax], 13
mov eax, dword ptr [rdi]
add rsp, 544
pop rbx
pop rdi
pop rsi
ret
It's quite a lot of assembly, but the key bit is that it:
- Has
ptr1inrdi. - Has
ptr2inrax. - Stores 42 into
ptr1. - Stores 13 into
ptr2. - Loads
ptr1again to return it.
Let's now add our [return: NoAlias] attribute:
[MethodImpl(MethodImplOptions.NoInlining)]
[return: NoAlias]
unsafe int* BumpAlloc(int* alloca)
{
int location = alloca[0]++;
return alloca + location;
}
unsafe int Func()
{
int* alloca = stackalloc int[128];
// Store our size at the start of the alloca.
alloca[0] = 1;
int* ptr1 = BumpAlloc(alloca);
int* ptr2 = BumpAlloc(alloca);
*ptr1 = 42;
*ptr2 = 13;
return *ptr1;
}
Which produces:
push rsi
push rdi
push rbx
sub rsp, 544
lea rcx, [rsp + 36]
movabs rax, offset memset
mov r8d, 508
xor edx, edx
call rax
mov dword ptr [rsp + 32], 1
movabs rbx, offset "BumpAlloc(int* alloca)"
lea rsi, [rsp + 32]
mov rcx, rsi
call rbx
mov rdi, rax
mov rcx, rsi
call rbx
mov dword ptr [rdi], 42
mov dword ptr [rax], 13
mov eax, 42
add rsp, 544
pop rbx
pop rdi
pop rsi
ret
And notice that the compiler doesn't reload ptr2 but simply moves 42 into the return register.
[return: NoAlias] should only ever be used on functions that are 100% guaranteed to produce a unique pointer, like with the bump-allocating example above, or with things like malloc. It is also important to note that the compiler aggressively inlines functions for performance considerations, and so small functions like the above will likely be inlined into their parents and produce the same result without the attribute (which is why we had to force no-inlining on the called function).
Function Cloning for Better Aliasing Deduction
For function calls where Burst knows about the aliasing between parameters to the function, Burst can infer the aliasing and propagate this onto the called function to allow for greater optimization opportunities. Lets look at an example:
[MethodImpl(MethodImplOptions.NoInlining)]
int Bar(ref int a, ref int b)
{
a = 42;
b = 13;
return a;
}
int Foo()
{
var a = 53;
var b = -2;
return Bar(ref a, ref b);
}
Previously the code for Bar would be:
mov dword ptr [rcx], 42
mov dword ptr [rdx], 13
mov eax, dword ptr [rcx]
ret
This is because within the Bar function, the compiler did not know the aliasing of a and b. This is in line with what other compiler technologies will do with this code snippet.
Burst is smarter than this though, and through a process of function cloning Burst will create a copy of Bar where the aliasing properties of a and b are known not to alias, and replace the original call to Bar with a call to the copy. This results in the following assembly:
mov dword ptr [rcx], 42
mov dword ptr [rdx], 13
mov eax, 42
ret
Which as we can see doesn't perform the second load from a.
Aliasing Checks
Since aliasing is so key to the compilers ability to optimize for performance, we've added some aliasing intrinsics:
Unity.Burst.CompilerServices.Aliasing.ExpectAliasedexpects that the two pointers do alias, and generates a compiler error if not.Unity.Burst.CompilerServices.Aliasing.ExpectNotAliasedexpects that the two pointers do not alias, and generates a compiler error if not.
An example:
using static Unity.Burst.CompilerServices.Aliasing;
[BurstCompile]
private struct CopyJob : IJob
{
[ReadOnly]
public NativeArray<float> Input;
[WriteOnly]
public NativeArray<float> Output;
public unsafe void Execute()
{
// NativeContainer attributed structs (like NativeArray) cannot alias with each other in a job struct!
ExpectNotAliased(Input.getUnsafePtr(), Output.getUnsafePtr());
// NativeContainer structs cannot appear in other NativeContainer structs.
ExpectNotAliased(in Input, in Output);
ExpectNotAliased(in Input, Input.getUnsafePtr());
ExpectNotAliased(in Input, Output.getUnsafePtr());
ExpectNotAliased(in Output, Input.getUnsafePtr());
ExpectNotAliased(in Output, Output.getUnsafePtr());
// But things definitely alias with themselves!
ExpectAliased(in Input, in Input);
ExpectAliased(Input.getUnsafePtr(), Input.getUnsafePtr());
ExpectAliased(in Output, in Output);
ExpectAliased(Output.getUnsafePtr(), Output.getUnsafePtr());
}
}
These checks will only be ran when optimizations are enabled - since proper aliasing deduction is intrinsically linked to the optimizers ability to see through functions via inlining.
Loop Vectorization
Loop vectorization is one of the ways that Burst improves performance. Let's say you have code like this:
[MethodImpl(MethodImplOptions.NoInlining)]
private static unsafe void Bar([NoAlias] int* a, [NoAlias] int* b, int count)
{
for (var i = 0; i < count; i++)
{
a[i] += b[i];
}
}
public static unsafe void Foo(int count)
{
var a = stackalloc int[count];
var b = stackalloc int[count];
Bar(a, b, count);
}
The compiler is able to convert that scalar loop in Bar into a vectorized loop. Instead of looping over a single value at a time,
the compiler generates code that loops over multiple values at the same time, producing faster code essentially for free. Here is the
x64 assembly generated for AVX2 for the loop in Bar above:
.LBB1_4:
vmovdqu ymm0, ymmword ptr [rdx + 4*rax]
vmovdqu ymm1, ymmword ptr [rdx + 4*rax + 32]
vmovdqu ymm2, ymmword ptr [rdx + 4*rax + 64]
vmovdqu ymm3, ymmword ptr [rdx + 4*rax + 96]
vpaddd ymm0, ymm0, ymmword ptr [rcx + 4*rax]
vpaddd ymm1, ymm1, ymmword ptr [rcx + 4*rax + 32]
vpaddd ymm2, ymm2, ymmword ptr [rcx + 4*rax + 64]
vpaddd ymm3, ymm3, ymmword ptr [rcx + 4*rax + 96]
vmovdqu ymmword ptr [rcx + 4*rax], ymm0
vmovdqu ymmword ptr [rcx + 4*rax + 32], ymm1
vmovdqu ymmword ptr [rcx + 4*rax + 64], ymm2
vmovdqu ymmword ptr [rcx + 4*rax + 96], ymm3
add rax, 32
cmp r8, rax
jne .LBB1_4
As can be seen, the loop has been unrolled and vectorized so that it is has 4 vpaddd instructions, each calculating 8 integer additions,
for a total of 32 integer additions per loop iteration.
This is great! However, loop vectorization is notoriously brittle. As an example, let's introduce a seemingly innocuous branch like this:
[MethodImpl(MethodImplOptions.NoInlining)]
private static unsafe void Bar([NoAlias] int* a, [NoAlias] int* b, int count)
{
for (var i = 0; i < count; i++)
{
if (a[i] > b[i])
{
break;
}
a[i] += b[i];
}
}
Now the assembly changes to this:
.LBB1_3:
mov r9d, dword ptr [rcx + 4*r10]
mov eax, dword ptr [rdx + 4*r10]
cmp r9d, eax
jg .LBB1_4
add eax, r9d
mov dword ptr [rcx + 4*r10], eax
inc r10
cmp r8, r10
jne .LBB1_3
This loop is completely scalar and only has 1 integer addition per loop iteration. This is not good! In this simple case, an experienced developer would probably spot that adding the branch will break auto-vectorization. But in more complex real-life code it can be difficult to spot.
To help with this problem, Burst includes experimental at present intrinsics (Loop.ExpectVectorized() and Loop.ExpectNotVectorized()) to express loop vectorization
assumptions, and have them validated at compile-time. For example, we can change the original Bar implementation to:
[MethodImpl(MethodImplOptions.NoInlining)]
private static unsafe void Bar([NoAlias] int* a, [NoAlias] int* b, int count)
{
for (var i = 0; i < count; i++)
{
Unity.Burst.CompilerServices.Loop.ExpectVectorized();
a[i] += b[i];
}
}
Burst will now validate, at compile-time, that the loop has indeed been vectorized. If the loop is not vectorized, Burst will emit a compiler error. For example, if we do this:
[MethodImpl(MethodImplOptions.NoInlining)]
private static unsafe void Bar([NoAlias] int* a, [NoAlias] int* b, int count)
{
for (var i = 0; i < count; i++)
{
Unity.Burst.CompilerServices.Loop.ExpectVectorized();
if (a[i] > b[i])
{
break;
}
a[i] += b[i];
}
}
then Burst will emit the following error at compile-time:
LoopIntrinsics.cs(6,9): Burst error BC1321: The loop is not vectorized where it was expected that it is vectorized.
As these intrinsics are experimental, they need to be enabled with the UNITY_BURST_EXPERIMENTAL_LOOP_INTRINSICS preprocessor define.
Note that these loop intrinsics should not be used inside
ifstatements. Burst does not currently prevent this from happening, but in a future release this will be a compile-time error.
Compiler Options
When compiling a job, you can change the behavior of the compiler:
- Using a different accuracy for the math functions (sin, cos...)
- Allowing the compiler to re-arrange the floating point calculations by relaxing the order of the math computations.
- Forcing a synchronous compilation of the Job (only for the Editor/JIT case)
- Using internal compiler options (not yet detailed)
These flags can be set through the [BurstCompile] attribute, for example [BurstCompile(FloatPrecision.Med, FloatMode.Fast)]
FloatPrecision
The accuracy is defined by the following enumeration:
public enum FloatPrecision
{
/// <summary>
/// Use the default target floating point precision - <see cref="FloatPrecision.Medium"/>.
/// </summary>
Standard = 0,
/// <summary>
/// Compute with an accuracy of 1 ULP - highly accurate, but increased runtime as a result, should not be required for most purposes.
/// </summary>
High = 1,
/// <summary>
/// Compute with an accuracy of 3.5 ULP - considered acceptable accuracy for most tasks.
/// </summary>
Medium = 2,
/// <summary>
/// Compute with an accuracy lower than or equal to <see cref="FloatPrecision.Medium"/>, with some range restrictions (defined per function).
/// </summary>
Low = 3,
}
Currently, the implementation is only providing the following accuracy:
FloatPrecision.Standardis equivalent toFloatPrecision.Mediumproviding an accuracy of 3.5 ULP. This is the default value.FloatPrecision.Highprovides an accuracy of 1.0 ULP.FloatPrecision.Mediumprovides an accuracy of 3.5 ULP.FloatPrecision.Lowhas an accuracy defined per function, and functions may specify a restricted range of valid inputs.
Using the FloatPrecision.Standard accuracy should be largely enough for most games.
An ULP (unit in the last place or unit of least precision) is the spacing between floating-point numbers, i.e., the value the least significant digit represents if it is 1.
Note: The FloatPrecision Enum was named Accuracy in early versions of the Burst API.
FloatPrecision.Low
The following table describes the precision and range restrictions for using the FloatPrecision.Low mode. Any function not described in the table will inherit the ULP requirement from FloatPrecision.Medium.
| Function | Precision | Range |
|---|---|---|
| Unity.Mathematics.math.sin(x) | 350.0 ULP | |
| Unity.Mathematics.math.cos(x) | 350.0 ULP | |
| Unity.Mathematics.math.exp(x) | 350.0 ULP | |
| Unity.Mathematics.math.exp2(x) | 350.0 ULP | |
| Unity.Mathematics.math.exp10(x) | 350.0 ULP | |
| Unity.Mathematics.math.log(x) | 350.0 ULP | |
| Unity.Mathematics.math.log2(x) | 350.0 ULP | |
| Unity.Mathematics.math.log10(x) | 350.0 ULP | |
| Unity.Mathematics.math.pow(x, y) | 350.0 ULP | Negative x to the power of a fractional y are not supported. |
Compiler floating point math mode
The compiler floating point math mode is defined by the following enumeration:
/// <summary>
/// Represents the floating point optimization mode for compilation.
/// </summary>
public enum FloatMode
{
/// <summary>
/// Use the default target floating point mode - <see cref="FloatMode.Strict"/>.
/// </summary>
Default = 0,
/// <summary>
/// No floating point optimizations are performed.
/// </summary>
Strict = 1,
/// <summary>
/// Reserved for future.
/// </summary>
Deterministic = 2,
/// <summary>
/// Allows algebraically equivalent optimizations (which can alter the results of calculations), it implies :
/// <para/> optimizations can assume results and arguments contain no NaNs or +/- Infinity and treat sign of zero as insignificant.
/// <para/> optimizations can use reciprocals - 1/x * y , instead of y/x.
/// <para/> optimizations can use fused instructions, e.g. madd.
/// </summary>
Fast = 3,
}
FloatMode.Defaultis defaulting toFloatMode.StrictFloatMode.Strict: The compiler is not performing any re-arrangement of the calculation and will be careful at respecting special floating point values (denormals, NaN...). This is the default value.FloatMode.Fast: The compiler can perform instructions re-arrangement and/or using dedicated/less precise hardware SIMD instructions.FloatMode.Deterministic: Reserved for future, when Burst will provide support for deterministic mode
Typically, some hardware can support Multiply and Add (e.g mad a * b + c) into a single instruction. Using the Fast calculation can allow these optimizations.
The reordering of these instructions can lead to a lower accuracy.
Using the FloatMode.Fast compiler floating point math mode can be used for many scenarios where the exact order of the calculation and the uniform handling of NaN values are not strictly required.
Assume Intrinsics
Being able to tell the compiler that an integer lies within a certain range can open up optimization opportunities. The AssumeRange attribute allows users to tell the compiler that a given scalar-integer lies within a certain constrained range:
[return:AssumeRange(0u, 13u)]
static uint WithConstrainedRange([AssumeRange(0, 26)] int x)
{
return (uint)x / 2u;
}
The above code makes two promises to the compiler:
- That the variable
xis in the closed-interval range[0..26], or more plainly thatx >= 0 && x <= 26. - That the return value from
WithConstrainedRangeis in the closed-interval range[0..13], or more plainly thatx >= 0 && x <= 13.
These assumptions are fed into the optimizer and allow for better codegen as a result. There are some restrictions:
- You can only place these on scalar-integer (signed or unsigned) types.
- The type of the range arguments must match the type being attributed.
We've also added in some deductions for the .Length property of NativeArray and NativeSlice to tell the optimizer that these always return non-negative integers.
static bool IsLengthNegative(NativeArray<float> na)
{
// The compiler will always replace this with the constant false!
return na.Length < 0;
}
Lets assume you have your own container:
struct MyContainer
{
public int Length;
// Some other data...
}
And you wanted to tell Burst that Length was always a positive integer. You would do that like so:
struct MyContainer
{
private int _length;
[return: AssumeRange(0, int.MaxValue)]
private int LengthGetter()
{
return _length;
}
public int Length
{
get => LengthGetter();
set => _length = value;
}
// Some other data...
}
Unity.Mathematics
The Unity.Mathematics provides vector types (float4, float3...) that are directly mapped to hardware SIMD registers.
Also, many functions from the math type are also mapped directly to hardware SIMD instructions.
Note that currently, for an optimal usage of this library, it is recommended to use SIMD 4 wide types (
float4,int4,bool4...)
Generic Jobs
As described in AOT vs JIT, there are currently two modes Burst will compile a Job:
- When in the Editor, it will compile the Job when it is scheduled (sometimes called JIT mode).
- When building a Standalone Player, it will compile the Job as part of the build player (AOT mode).
If the Job is a concrete type (not using generics), the Job will be compiled correctly in both modes.
In case of a generic Job, it can behave more unexpectedly.
While Burst supports generics, it has limited support for using generic Jobs or Function pointers. You could notice that a job scheduled at Editor time is running at full speed with Burst but not when used in a Standalone player. It is usually a problem related to generic Jobs.
A generic Job can be defined like this:
// Direct Generic Job
[BurstCompile]
struct MyGenericJob<TData> : IJob where TData : struct {
public void Execute() { ... }
}
or can be nested:
// Nested Generic Job
public class MyGenericSystem<TData> where TData : struct {
[BurstCompile]
struct MyGenericJob : IJob {
public void Execute() { ... }
}
public void Run()
{
var myJob = new MyGenericJob(); // implicitly MyGenericSystem<TData>.MyGenericJob
myJob.Schedule();
}
}
When the previous Jobs are being used like:
// Direct Generic Job
var myJob = new MyGenericJob<int>();
myJob.Schedule();
// Nested Generic Job
var myJobSystem = new MyGenericSystem<float>();
myJobSystem.Run();
In both cases in a standalone-player build, the Burst compiler will be able to detect that it has to compile MyGenericJob<int> and MyGenericJob<float> because the generic jobs (or the type surrounding it for the nested job) are used with fully resolved generic arguments (int and float).
But if these jobs are used indirectly through a generic parameter, the Burst compiler won't be able to detect the Jobs to compile at standalone-player build time:
public static void GenericJobSchedule<TData>() where TData: struct {
// Generic argument: Generic Parameter TData
// This Job won't be detected by the Burst Compiler at standalone-player build time.
var job = new MyGenericJob<TData>();
job.Schedule();
}
// The implicit MyGenericJob<int> will run at Editor time in full Burst speed
// but won't be detected at standalone-player build time.
GenericJobSchedule<int>();
Same restriction applies when declaring the Job in the context of generic parameter coming from a type:
// Generic Parameter TData
public class SuperJobSystem<TData>
{
// Generic argument: Generic Parameter TData
// This Job won't be detected by the Burst Compiler at standalone-player build time.
public MyGenericJob<TData> MyJob;
}
In summary, if you are using generic jobs, they need to be used directly with fully-resolved generic arguments (e.g
int,MyOtherStruct) but can't be used with a generic parameter indirection (e.gMyGenericJob<TContext>).
Regarding function pointers, they are more restricted as you can't use a generic delegate through a function pointer with Burst:
public delegate void MyGenericDelegate<T>(ref TData data) where TData: struct;
var myGenericDelegate = new MyGenericDelegate<int>(MyIntDelegateImpl);
// Will fail to compile this function pointer.
var myGenericFunctionPointer = BurstCompiler.CompileFunctionPointer<MyGenericDelegate<int>>(myGenericDelegate);
This limitation is due to a limitation of the .NET runtime to interop with such delegates.
Standalone Player support
The Burst compiler supports standalone players - see Burst AOT Requirements
Usage
With the exception of iOS, when burst compiles code for the standalone player, it will create a single dynamic library and place it into the standard plugins folder for that particular player type. e.g. on Windows, it is in the path Data/Plugins/lib_burst_generated.dll
This library is loaded by the Job system runtime the first time a burst compiled method is invoked.
For iOS, static libraries are generated instead, due to requirements for submitting to Test Flight.
Prior to Unity 2019.1, the settings for AOT compilation are shared with the Jobs Menu.
In later Unity versions (2019.1 and beyond), the settings for AOT compilation are configured via Burst AOT Settings.
Burst AOT Settings
When a project uses AOT compilation, you can control Burst behavior using the Burst AOT Settings section of the Project Settings window. The AOT settings override the Burst settings on the Jobs menu when you make a standalone build of your project.
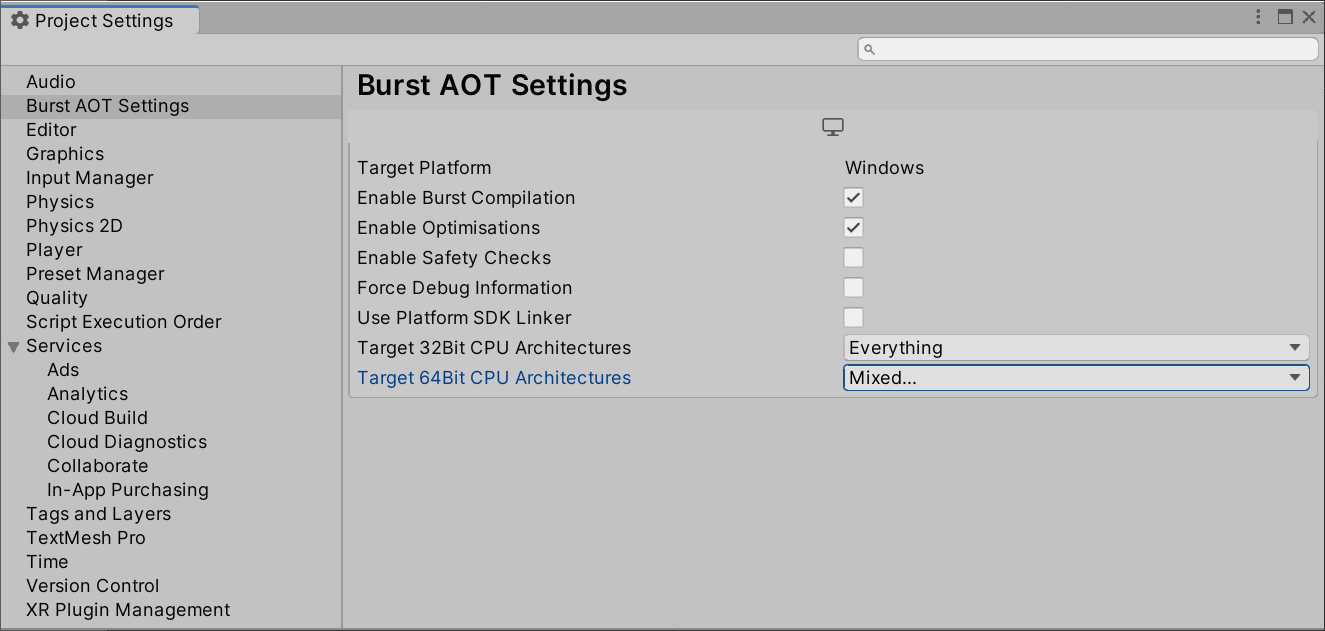
- Target Platform: Shows the current desktop platform - can be changed via the Unity Build Settings.. dialog.
- Enable Burst Compilation: Turns Burst entirely on/off for the currently selected platform.
- Enable Optimizations: Turns Burst optimizations on/off.
- Enable Safety Checks: Turns Burst safety checks on/off.
- Force Debug Information: Forces Burst to generate debug information (even in release standalone player builds). Care should be taken not to accidentally ship a build containing symbols.
- Use Platform SDK Linker: Disables cross compilation support (Only applicable to Windows/macOS/Linux standalone players) (see Burst AOT Requirements).
- Target 32Bit CPU Architectures: Allows you to specify the CPU architectures supported for 32 bit builds (shown when supported). The default is SSE2 and SSE4 selected.
- Target 64Bit CPU Architectures: Allows you to specify the CPU architectures supported for 64-bit builds (shown when supported). The default is SSE2 and AVX2 selected.
CPU Architecture is currently only supported for Windows, macOS, and Linux. Burst will generate a standalone player that supports the CPU architectures you have selected. A special dispatch is generated into the module, so that the code generated will detect the CPU being used and select the appropriate CPU architecture at runtime.
You can set the Burst AOT settings as required for each of the supported platforms. The options are saved per platform as part of the project settings.
Note: The Burst AOT Settings are available in Unity 2019.1+.
Burst AOT Requirements
Desktop platforms with cross compilation enabled (the default behaviour)
Burst compilation for desktop platforms (macOS, Linux, Windows) no longer requires external toolchain support when building a standalone player (since Burst 1.3.0-preview.1). This should work out of the box, but can be disabled in Burst AOT Settings if needed.
Other platforms and desktops when cross compilation is disabled
If compiling for a non desktop platform, or you have disabled cross compilation support, then burst compilation requires specific platform compilation tools (similar to IL2CPP), the below table can be used to determine the current level of support for AOT compilation.
- If a host/target combination is not listed, it is at present not supported for burst compilation.
- If a target is not valid (missing tools/unsupported), burst compilation will not be used (may fail), but the target will still be built without burst optimisations.
| Host Editor Platform | Target Player Platform | Supported CPU Architectures | External Toolchain Requirements |
|---|---|---|---|
| Windows | Windows | x86 (SSE2, SSE4), x64 (SSE2, SSE4) |
Visual Studio (can be installed via Add Component in Unity Install) and C++ Build Tools for Visual Studio (use visual studio installer to add this). Windows 10 SDK |
| Windows | Universal Windows Platform | x86 (SSE2, SSE4), x64 (SSE2, SSE4), ARM32 Thumb2/Neon32, ARMV8 AARCH64 |
Visual Studio 2017 Universal Windows Platform Development Workflow C++ Universal Platform Tools |
| Windows | Android | x86 SSE2, ARM32 Thumb2/Neon32, ARMV8 AARCH64 |
Android NDK 13 or higher - It is preferred to use the one installed by unity (via Add Component). Will fall back to the one specified by ANDROID_NDK_ROOT environment variable if the unity external tools settings are not configured. |
| Windows | Magic Leap | ARMV8 AARCH64 |
Lumin SDK must be installed via Magic Leap Package Manager and configured in the Unity Editor's External Tools Preferences. |
| Windows | Xbox One | x64 SSE4 |
Visual Studio 2015 Microsoft XDK |
| Windows | PS4 | x64 SSE4 |
Minimum PS4 SDK version 5.0.0 |
| Windows | Nintendo Switch | ARMV8 AARCH64 |
Minimum Nintendo Switch NDK 8.2.0 Requires 2019.3 Unity Editor or greater |
| macOS | macOS | x86 (SSE2, SSE4), x64 (SSE2, SSE4) |
Xcode with command line tools installed (xcode-select --install) |
| macOS | iOS | ARM32 Thumb2/Neon32, ARMV8 AARCH64 |
Xcode with command line tools installed (xcode-select --install) Requires Unity 2018.3.6f1+ or Unity 2019.1.0b4 or later |
| macOS | Android | x86 SSE2, ARM32 Thumb2/Neon32, ARMV8 AARCH64 |
Android NDK 13 or higher - It is preferred to use the one installed by unity (via Add Component). Will fall back to the one specified by ANDROID_NDK_ROOT environment variable if the unity external tools settings are not configured. |
| macOS | Magic Leap | ARMV8 AARCH64 |
Lumin SDK must be installed via Magic Leap Package Manager and configured in the Unity Editor's External Tools Preferences. |
| Linux | Linux | x86 (SSE2, SSE4), x64 (SSE2, SSE4) |
Clang or Gcc tool chains. |
Notes:
- Burst by default now supports cross compilation between desktop platforms (macOS/Linux/Windows)
- The UWP build will always compile all four targets (x86, x64, ARMv7 and ARMv8).
Burst Targets
When Burst compiles for multiple targets during an AOT build, it has to do seperate compilations underneath to support this. For example, if you were compiling for X64_SSE2 and X64_SSE4 the compiler will have to do two separate compilations underneath to generate code for each of the targets you choose.
To keep the combinations of targets to a minimum, we make certain Burst targets require multiple processor instruction sets underneath:
SSE4.2is gated on havingSSE4.2andPOPCNTinstruction sets.AVX2is gated on havingAVX2,FMA, andF16Cinstruction sets.
Known issues
- The maximum target CPU is currently hardcoded per platform. For standalone builds that target desktop platforms (Windows/Linux/macOS) you can choose the supported targets via Burst AOT Settings. For other platforms see the table above.
- Building iOS player from Windows will not use Burst, (see Burst AOT Requirements)
- Building Android player from Linux will not use Burst, (see Burst AOT Requirements)
- If you change the burst package version (via update for example), you need to close and restart the editor. A warning is now displayed to this effect.
- Function pointers are not working in playmode tests before 2019.3. The feature will be backported.
- Struct with explicit layout can generate non optimal native code
BurstCompiler.SetExecutionModedoes not affect the runtime yet for deterministic mode- Burst does not support scheduling generic Jobs through generic methods. While this would work in the editor, it will not work in the standalone player.
Some of these issues may be resolved in a future release of Burst.
Presentations
Conference presentations given by the Burst team:
- Getting started with Burst - Unite Copenhagen 2019 (slides)
- Intrinsics: Low-level engine development with Burst - Unite Copenhagen 2019 (slides)
- Behind the burst compiler, converting .NET IL to highly optimized native code - DotNext 2018
- Deep Dive into the Burst Compiler - Unite LA 2018
- C# to Machine Code - GDC 2018
- Using the native debugger for Burst Compiled Code